class: center, middle, inverse, title-slide # Reshaping and combining data in R ### Emma Vestesson ### The Health Foundation --- ## What we will cover today Session is aimed at advanced beginners and I will assume some familiarity with R and the tidyverse. You can find the slides here https://thf-evaluative-analytics.github.io/NHSR-wrangling-webinar/slides.html -- ### Coding along No need to code along, but if you want to, here is what you need: - `tidyverse`, `here` and `lubridate` packages installed and loaded. - data from github repo https://github.com/THF-evaluative-analytics/NHSR-wrangling-webinar -- We will focus on two packages - Reshaping data - tidyr - Joining data sets together - dplyr package --- class: middle, center ## What's your favourite R package? Please go to www.menti.com and enter code 68 57 82 7 --- ## Packages in R The first time you use it you need to install the package. ```r install.packages("tidyverse") ``` Load the package ```r library(tidyverse) library(lubridate) ``` --- ## The pipe Simplifying R code with pipes (%>%) nested statement ```r leave_house(get_dressed(get_out_of_bed(wake_up(me)))) ``` VS piped statement ```r me %>% wake_up() %>% get_out_of_bed() %>% get_dressed() %>% leave_house() ``` **Keyboard shortcut ctrl+shift +m** --- class: center, middle  --- class: ## Tidy data Data comes in all kinds of shapes and forms. We need a consistent way of storing data! -- 1. Each variable forms a column. 2. Each observation forms a row. 3. Each cell contains a single value.  --- # tidyr package `pivot_longer` - you will end up with more rows  `pivot_wider` - you will end up with more variables (or at least fewer rows)  --- ## Does this look familiar?  -- 👨👩👧 😄 -- 💻 😢 --- class: # Sitrep data Downloaded data from [NHSE website](https://www.england.nhs.uk/statistics/statistical-work-areas/winter-daily-sitreps/winter-daily-sitrep-2017-18-data/) and saved in R data format. ```r sitrep <- readRDS(here::here('data', 'sitrep.rds')) # all calls sitrep_60sec <- readRDS(here::here('data', 'sitrep_60sec.rds')) # calls answered within 60sec ``` ```r head(sitrep) ``` ``` ## # A tibble: 6 x 9 ## NHS_111_area_na… `26_Feb` `27_Feb` `28_Feb` `01_Mar` ## <chr> <dbl> <dbl> <dbl> <dbl> ## 1 North East Engl… 2272 1793 1724 1707 ## 2 North West inc … 3433 3047 3180 2966 ## 3 Yorkshire And H… 3670 3144 2892 3289 ## 4 Lincolnshire NH… 359 355 503 446 ## 5 Luton & Bedford… 410 361 363 292 ## 6 Nottinghamshire… 771 732 825 788 ## # … with 4 more variables: `02_Mar` <dbl>, ## # `03_Mar` <dbl>, `04_Mar` <dbl>, year <dbl> ``` --- class: ## Potential analysis Plot the total number of calls over time Create 7 day rolling average Summarise by region -- .pull-right[ <img src="https://pics.me.me/http-killer-headache-yeah-its-like-this-nemecrunch-com-5920580.png" > ] -- .pull-left[ **Very difficult with the current set up** ] --- class: # What is a sensible next step? We have got a data set. What is a sensible next step? Please go to mentimeter 1. make the data longer 1. make the data wider 1. nah don't bother, it is fine as it is --- class: left, middle ## Let's make the data long ```r sitrep_long <- sitrep %>% pivot_longer( * cols=-c(NHS_111_area_name, year), names_to='day_month', values_to='calls') ``` --- class: left, middle ## Let's make the data long ```r sitrep_long <- sitrep %>% pivot_longer( cols=-c(NHS_111_area_name, year), * names_to='day_month', values_to='calls') ``` --- class: left, middle ## Let's make the data long ```r sitrep_long <- sitrep %>% pivot_longer( cols=-c(NHS_111_area_name, year), names_to='day_month', * values_to='calls') ``` --- class: middle Our data is long and easier to work with! ```r head(sitrep_long) ``` ``` ## # A tibble: 6 x 4 ## NHS_111_area_name year day_month calls ## <chr> <dbl> <chr> <dbl> ## 1 North East England NHS 111 2018 26_Feb 2272 ## 2 North East England NHS 111 2018 27_Feb 1793 ## 3 North East England NHS 111 2018 28_Feb 1724 ## 4 North East England NHS 111 2018 01_Mar 1707 ## 5 North East England NHS 111 2018 02_Mar 1819 ## 6 North East England NHS 111 2018 03_Mar 3998 ``` --- Fix the date ```r sitrep_long <- sitrep_long %>% mutate(date=paste(day_month, year), date=dmy(date)) head(sitrep_long) ``` ``` ## # A tibble: 6 x 5 ## NHS_111_area_name year day_month calls date ## <chr> <dbl> <chr> <dbl> <date> ## 1 North East England NHS… 2018 26_Feb 2272 2018-02-26 ## 2 North East England NHS… 2018 27_Feb 1793 2018-02-27 ## 3 North East England NHS… 2018 28_Feb 1724 2018-02-28 ## 4 North East England NHS… 2018 01_Mar 1707 2018-03-01 ## 5 North East England NHS… 2018 02_Mar 1819 2018-03-02 ## 6 North East England NHS… 2018 03_Mar 3998 2018-03-03 ``` --- Calculate total calls by region ```r sitrep_calls_by_region <- sitrep_long %>% group_by(NHS_111_area_name) %>% summarise(total_calls_region=sum(calls)) head(sitrep_calls_by_region) ``` ``` ## # A tibble: 6 x 2 ## NHS_111_area_name total_calls_regi… ## <chr> <dbl> ## 1 Banes & Wiltshire NHS 111 3098 ## 2 Berkshire NHS 111 NA ## 3 Bristol, North Somerset & South Glouc… 6199 ## 4 Buckinghamshire NHS 111 NA ## 5 Cambridgeshire & Peterborough NHS 111 4634 ## 6 Cornwall NHS 111 3271 ``` --- Plot calls over time ```r sitrep_long %>% group_by(date) %>% summarise(total_calls_region=sum(calls, na.rm=TRUE)) %>% ggplot(aes(x=date, y=total_calls_region)) + geom_point(colour='purple') + theme_minimal() + scale_x_date(date_labels = '%Y-%m-%d') + scale_y_continuous(limits = c(0, NA), labels=scales::comma) + labs(x='', y='', title='Daily calls to NHS 111') ``` <img src="slides_files/figure-html/unnamed-chunk-9-1.png" width="504" /> --- You can also go back to a wide format eg after calculating the cumulative sum of calls. ```r sitrep_wide <- sitrep_long %>% group_by(NHS_111_area_name) %>% arrange(date) %>% mutate(cum_call=cumsum(calls)) %>% pivot_wider(id_cols = c(NHS_111_area_name), values_from=cum_call, names_from=date) head(sitrep_wide) ``` ``` ## # A tibble: 6 x 8 ## # Groups: NHS_111_area_name [6] ## NHS_111_area_na… `2018-02-26` `2018-02-27` `2018-02-28` ## <chr> <dbl> <dbl> <dbl> ## 1 North East Engl… 2272 4065 5789 ## 2 North West inc … 3433 6480 9660 ## 3 Yorkshire And H… 3670 6814 9706 ## 4 Lincolnshire NH… 359 714 1217 ## 5 Luton & Bedford… 410 771 1134 ## 6 Nottinghamshire… 771 1503 2328 ## # … with 4 more variables: `2018-03-01` <dbl>, ## # `2018-03-02` <dbl>, `2018-03-03` <dbl>, ## # `2018-03-04` <dbl> ``` --- The `us_rent_income` dataset contains information about median income and rent for each state in the US for 2017. ```r us_rent_income ``` ``` ## # A tibble: 104 x 5 ## GEOID NAME variable estimate moe ## <chr> <chr> <chr> <dbl> <dbl> ## 1 01 Alabama income 24476 136 ## 2 01 Alabama rent 747 3 ## 3 02 Alaska income 32940 508 ## 4 02 Alaska rent 1200 13 ## 5 04 Arizona income 27517 148 ## 6 04 Arizona rent 972 4 ## 7 05 Arkansas income 23789 165 ## 8 05 Arkansas rent 709 5 ## 9 06 California income 29454 109 ## 10 06 California rent 1358 3 ## # … with 94 more rows ``` --- ```r us_wide <- pivot_wider(us_rent_income, names_from = variable, values_from = c(estimate, moe)) ``` ```r ggplot(us_wide, aes(x=estimate_income, estimate_rent)) + geom_point(colour='purple') + scale_y_continuous(limits=c(0, NA)) + scale_x_continuous(limits=c(0, NA)) + theme_minimal() + labs(x='Estimated income', y='Estimated rent') ``` <img src="slides_files/figure-html/unnamed-chunk-13-1.png" width="504" /> --- # Note! names_to and values_to from `pivot_longer()` should be quoted because you are creating new variables names_from and values_from from `pivot_wider()` should not be quoted because you are referring to variables that exist in your data frame. --- # Things get worse The `who` data set from the tidyr package shows a slightly more complicated example. ```r data('who') tail(who) ``` ``` ## # A tibble: 6 x 60 ## country iso2 iso3 year new_sp_m014 new_sp_m1524 ## <chr> <chr> <chr> <int> <int> <int> ## 1 Zimbab… ZW ZWE 2008 127 614 ## 2 Zimbab… ZW ZWE 2009 125 578 ## 3 Zimbab… ZW ZWE 2010 150 710 ## 4 Zimbab… ZW ZWE 2011 152 784 ## 5 Zimbab… ZW ZWE 2012 120 783 ## 6 Zimbab… ZW ZWE 2013 NA NA ## # … with 54 more variables: new_sp_m2534 <int>, ## # new_sp_m3544 <int>, new_sp_m4554 <int>, ## # new_sp_m5564 <int>, new_sp_m65 <int>, ## # new_sp_f014 <int>, new_sp_f1524 <int>, ## # new_sp_f2534 <int>, new_sp_f3544 <int>, ## # new_sp_f4554 <int>, new_sp_f5564 <int>, ## # new_sp_f65 <int>, new_sn_m014 <int>, ## # new_sn_m1524 <int>, new_sn_m2534 <int>, ## # new_sn_m3544 <int>, new_sn_m4554 <int>, ## # new_sn_m5564 <int>, new_sn_m65 <int>, ## # new_sn_f014 <int>, new_sn_f1524 <int>, ## # new_sn_f2534 <int>, new_sn_f3544 <int>, ## # new_sn_f4554 <int>, new_sn_f5564 <int>, ## # new_sn_f65 <int>, new_ep_m014 <int>, ## # new_ep_m1524 <int>, new_ep_m2534 <int>, ## # new_ep_m3544 <int>, new_ep_m4554 <int>, ## # new_ep_m5564 <int>, new_ep_m65 <int>, ## # new_ep_f014 <int>, new_ep_f1524 <int>, ## # new_ep_f2534 <int>, new_ep_f3544 <int>, ## # new_ep_f4554 <int>, new_ep_f5564 <int>, ## # new_ep_f65 <int>, newrel_m014 <int>, ## # newrel_m1524 <int>, newrel_m2534 <int>, ## # newrel_m3544 <int>, newrel_m4554 <int>, ## # newrel_m5564 <int>, newrel_m65 <int>, ## # newrel_f014 <int>, newrel_f1524 <int>, ## # newrel_f2534 <int>, newrel_f3544 <int>, ## # newrel_f4554 <int>, newrel_f5564 <int>, ## # newrel_f65 <int> ``` --- # Structure of variable names ``` ## [1] "newrel_f1524" "newrel_f2534" "newrel_f3544" ## [4] "newrel_f4554" "newrel_f5564" "newrel_f65" ``` new + method of diagnosis (rel = relapse, sn = negative pulmonary smear, sp = positive pulmonary smear, ep = extrapulmonary) + gender (f = female, m = male) + age group (014 = 0-14 yrs of age, 1524 = 15-24 years of age, etc.) --- ```r who %>% pivot_longer( * cols = new_sp_m014:newrel_f65, names_to = c("diagnosis", "gender", "age_group"), names_pattern = "new_?(.*)_(.)(.*)", values_to = "count" ) ``` --- ```r who %>% pivot_longer( cols = new_sp_m014:newrel_f65, * names_to = c("diagnosis", "gender", "age_group"), names_pattern = "new_?(.*)_(.)(.*)", values_to = "count" ) ``` --- ```r who %>% pivot_longer( cols = new_sp_m014:newrel_f65, names_to = c("diagnosis", "gender", "age_group"), * names_pattern = "new_?(.*)_(.)(.*)", values_to = "count" ) ``` --- ```r who %>% pivot_longer( cols = new_sp_m014:newrel_f65, names_to = c("diagnosis", "gender", "age_group"), names_pattern = "new_?(.*)_(.)(.*)", * values_to = "count" ) ``` --- class: # Combine datasets .pull-left[  ] .pull-right[] .pull-right[  ] --- class: top background-size: cover background-image: url(https://media.makeameme.org/created/danger-danger-everwhere.jpg) --- class: top background-image: url(https://www.memesmonkey.com/images/memesmonkey/e2/e24982369a32d97b56f206d303066b70.jpeg) background-position: bottom background-size: 800px 400px # Asking some big questions **Do I want to add more rows or more columns? ** --- background-image: url(https://miro.medium.com/max/1400/1*uG1vjoSQj7gMm8craCj2xA.png) background-position: bottom background-size: 800px 400px **More rows? Great!** `bind_rows()` - use to combine different datasets eg monthly gp appointments Columns with the same variable names will be stacked but check for changes to variable names. --- More columns? OK this is slightly more complicated but dplyr will be your friend. `bind_cols()` - I rarely use it - doesn't respect the order of the observations If we have a variable (or many) that identify your observations then we can use join functions from `dplyr`. If you know sql, this is your lucky day as the syntax is very similar. --- ## Mutating joins A mutating join allows you to combine variables from two tables. It first matches observations by their keys, then copies across variables from one table to the other. - inner_join(x,y) only keeps observations where in both - full_join(x,y) keeps all observations even if not in both - left_join(x,y) keeps all observations in x - right_join(x,y) keeps all observations in y 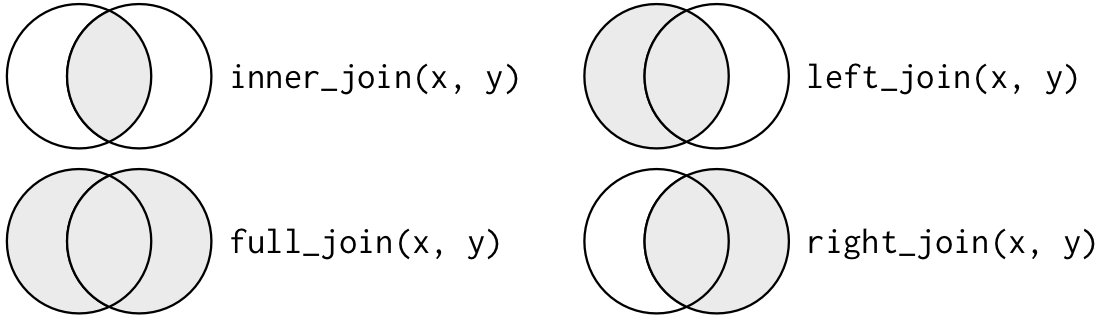 --- Let's revisit the NHS 111 data from before. ### All calls ``` ## # A tibble: 6 x 5 ## NHS_111_area_name year day_month calls date ## <chr> <dbl> <chr> <dbl> <date> ## 1 North East England NHS… 2018 26_Feb 2272 2018-02-26 ## 2 North East England NHS… 2018 27_Feb 1793 2018-02-27 ## 3 North East England NHS… 2018 28_Feb 1724 2018-02-28 ## 4 North East England NHS… 2018 01_Mar 1707 2018-03-01 ## 5 North East England NHS… 2018 02_Mar 1819 2018-03-02 ## 6 North East England NHS… 2018 03_Mar 3998 2018-03-03 ``` ### Calls answered within 60 seconds ``` ## # A tibble: 6 x 5 ## NHS_111_area_name year day_month calls date_60sec ## <chr> <dbl> <chr> <dbl> <date> ## 1 North East England NHS… 2018 26-Feb 1957 2018-02-26 ## 2 North East England NHS… 2018 27-Feb 1787 2018-02-27 ## 3 North East England NHS… 2018 28-Feb 1654 2018-02-28 ## 4 North East England NHS… 2018 01-Mar 1661 2018-03-01 ## 5 North East England NHS… 2018 02-Mar 1781 2018-03-02 ## 6 North East England NHS… 2018 03-Mar 3396 2018-03-03 ``` --- Mentimeter time! I want to combine the two data sets using the region name and the date. I want to keep all observations, even ones that do not exist in both data sets. Which type of join should I use? 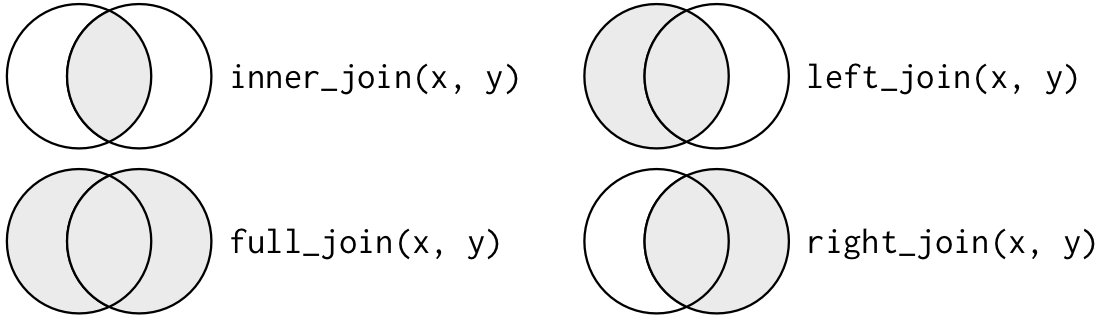 --- class: middle ```r sitrep_full <- full_join(sitrep_long, sitrep_60sec_long, by=c('NHS_111_area_name', 'date'='date_60sec'), suffix=c('_all','_60sec') ) ``` Worth noting - you can add a suffix for any variables that appear in both datasets - you can join on multiple variables - the variables you merge on do not need to have the same name --- ## Filtering joins Filtering joins match observations in the same way as mutating joins, but affect the observations, not the variables. - anti_join(x,y) drops all observations in x that have a match in y - semi_join(x,y) keeps all observations in x that have a match in y (similar to inner_join but no columns are added) <img src="https://psyteachr.github.io/msc-data-skills/images/joins/anti_join.png" height=300 > --- We have another data set called `regions` with the region, a region code and the area name ```r regions <- readRDS(here::here('data', 'regions.rds')) head(regions) ``` ``` ## region code nhs_111_area_name ## 1 North 111AA1 North East England NHS 111 ## 2 North 111AF8 North West inc Blackpool NHS 111 ## 3 North 111AD9 Yorkshire And Humber NHS 111 ## 4 Midlands & East 111AA2 Lincolnshire NHS 111 ## 5 Midlands & East 111AG7 Luton & Bedfordshire NHS 111 ## 6 Midlands & East 111AA4 Nottinghamshire NHS 111 ``` --- # Mentimeter time I want to check that all areas appear in the region file. What join function should I use? 1. left_join(sitrep_full, region) 1. anti_join(sitrep_full, region) 1. semi_join(sitrep_full, region) --- We also have a dataset with some areas of special interest. ```r areas_of_interest <- readRDS(here::here('data', 'areas_of_interest.rds')) head(areas_of_interest) ``` ``` ## region code nhs_111_area_name ## 1 North 111AA1 North East England NHS 111 ## 2 North 111AF8 North West inc Blackpool NHS 111 ## 3 Midlands & East 111AC3 North Essex NHS 111 ## 4 Midlands & East 111AC6 Northamptonshire NHS 111 ## 5 London 111AA7 Inner North West London NHS 111 ## 6 London 111AD4 North West London NHS 111 ``` --- # Mentimeter time I want to use one the join functions to only keep the observations in `sitrep_full` that also appear in `areas_of_interest` but I don't want to keep any of the variables from `areas_of_interest`. Which statment will do want I want? 1. anti_join(sitrep_full, areas_of_interest, by=c('NHS_111_area_name'='nhs_111_area_name')) 1. semi_join(sitrep_full, areas_of_interest, by=c('NHS_111_area_name'='nhs_111_area_name')) 1. inner_join(sitrep_full, areas_of_interest, by=c('NHS_111_area_name'='nhs_111_area_name')) --- class: middle Thank you for listening!